
Weighted Clustering with Minimum-Maximum Cluster Sizes, Greenfield Analysis
This post provides a center of gravity based algorithm for a greenfield analysis. Algorithm is based on k-means clustering enhanced with optimization.

Greenfield Analysis
Greenfield analysis is a quick way to identify optimal distribution center locations for a given demand network. The analysis answers the following questions:
- Where should distribution centers be geographically located to minimize cost?
- Which customers will be supplied from each distribution center?
Problem
We consider a network of customers where demand for each customer is satisfied by a distribution center. Figure 1 shows the customer locations and corresponding annual demand.
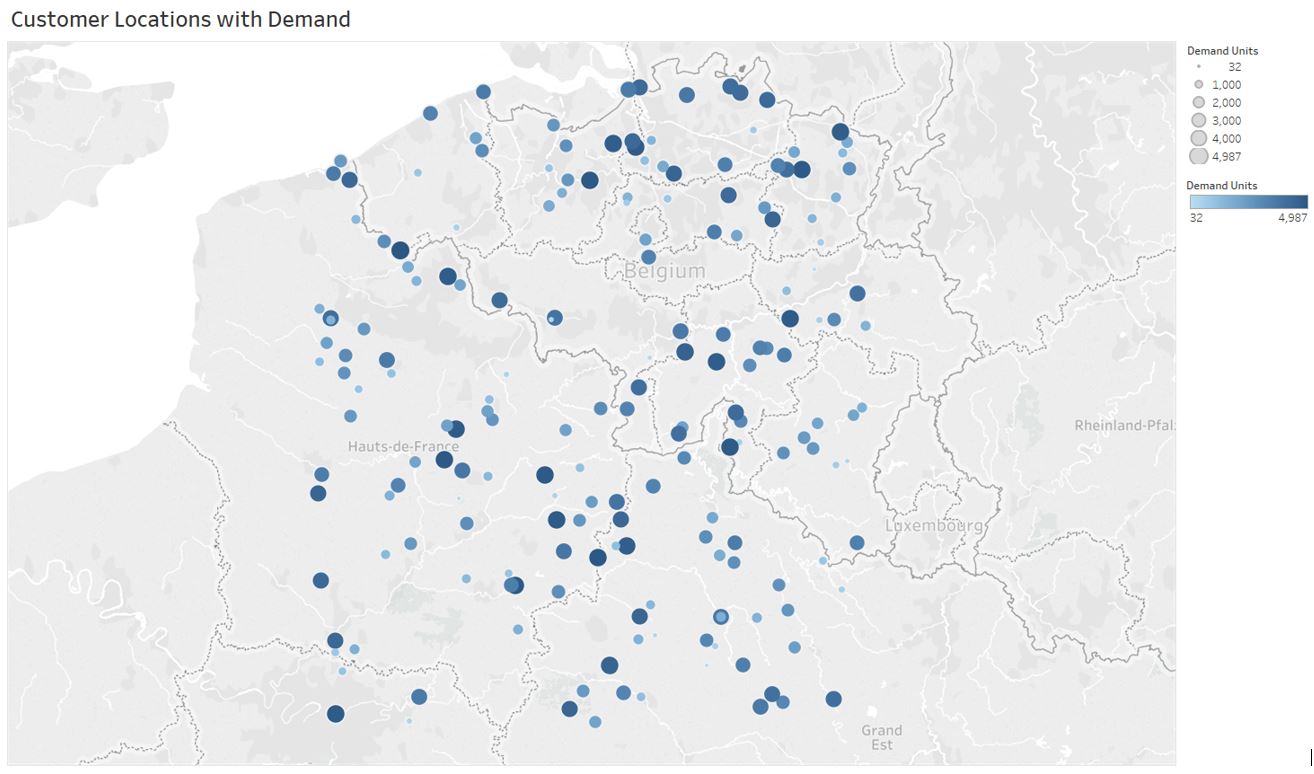 |
|---|
| Figure 1: Customer demand map |
It is assumed that any location can be selected for a distribution center location.
We answer the following questions as a result of the analysis:
- How many distribution centers are required?
- Where should each distribution center be located?
- How customers should be allocated to the distribution centers?
Algorithm
Algorithm is based on the center of gravity approach and selects the each distribution center locations such that total weighted distance to customers is minimized.
We first provide the following definitions related to the distribution network.
Let be the total number of distribution centers. Let be the set of distribution centers and be the set of customers allocated to the distribution center . Each distribution center has latitude and longitude, and , respectively. Let be the maximum distance covered by the center . Let and be the minimum and maximum number of customers can be allocated to center , respectively.
Let be the set of customers. Similar to distribution centers, each customer has latitude and longitude, and , respectively. Let be the total demand for the customer .
Let be the total weighted distance at iteration .
Let be the distance from the center to customer . Each is defined using the Haversine distance formula which calculates the shortest distance between two points on a sphere using their latitudes and longitudes measured along the surface. You can find more detailed explanation at the Wikipedia page.
The algorithm consists of the following steps:
Step 0: Set . For given , create randomly. Let .
Step 1: Set . For each , , , , , and , run a binary allocation model to determine . Let .
Step 2: If , then stop. Otherwise, set and . Repeat Steps 1-2 until .
Allocation of Customers to Distribution Centers
Once cluster centers are determined, we apply a binary model to allocate customers to distribution centers.
In addition to parameters defined in the Algorithm section, let be the binary variable for assigning center to customer .
The following is the binary program for allocating customers to distribution centers.
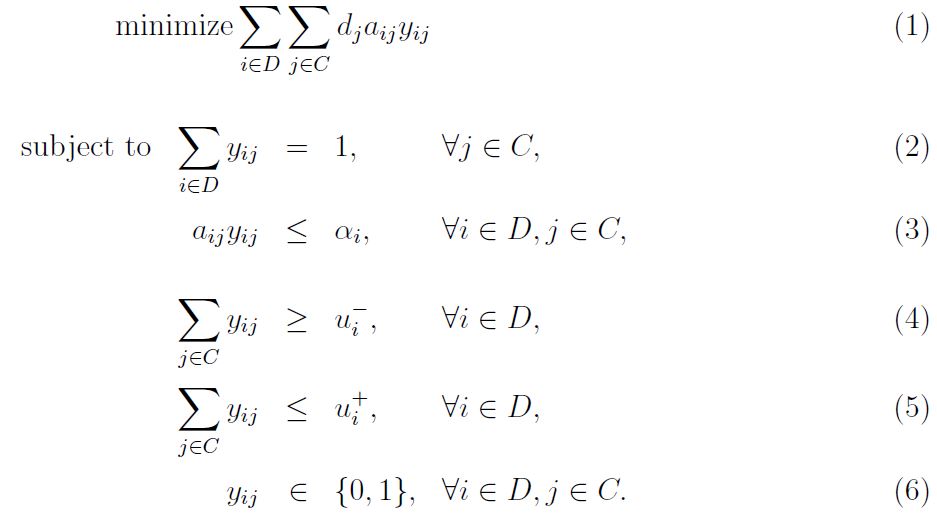
The objective of the model minimizes the total weighted distance. Constraint ensures that each customer is allocated to a center. There exists a maximum distance can be covered by each center . Each center has minimum and maximum number of allocated customers as in and , respectively. Center to customer allocation is binaries as in .
Implementation
The algorithm is implemented in Python. Google OR Tools is used to solve the allocation problem.
You can find the source code at the Greenfield_With_Weighted_Kmeans repository on GitHub.
Application
The algorithm is applied on the given problem. We iterate the algorithm for . Figure 2 shows run results.
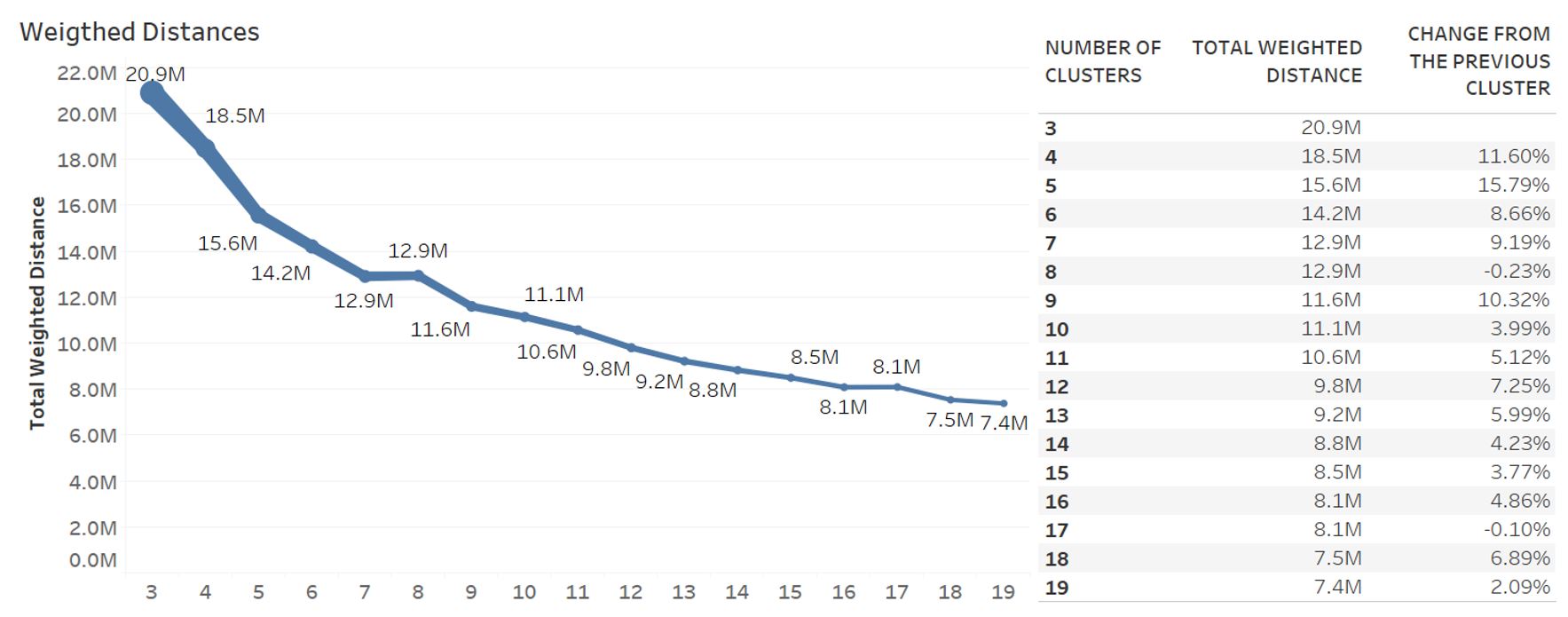 |
|---|
| Figure 2: Results for |
Total weighted distance decreases as the number of clusters increases. More specifically, From to , the total weighted distance is reduced by 39%. We find that is the best configuration since objective function improves slightly for and opening a new distribution center is costly.
Figure 3 shows iteration steps for . Algorithm converges quickly in the first three iterations and the total weighted distance reduces by .
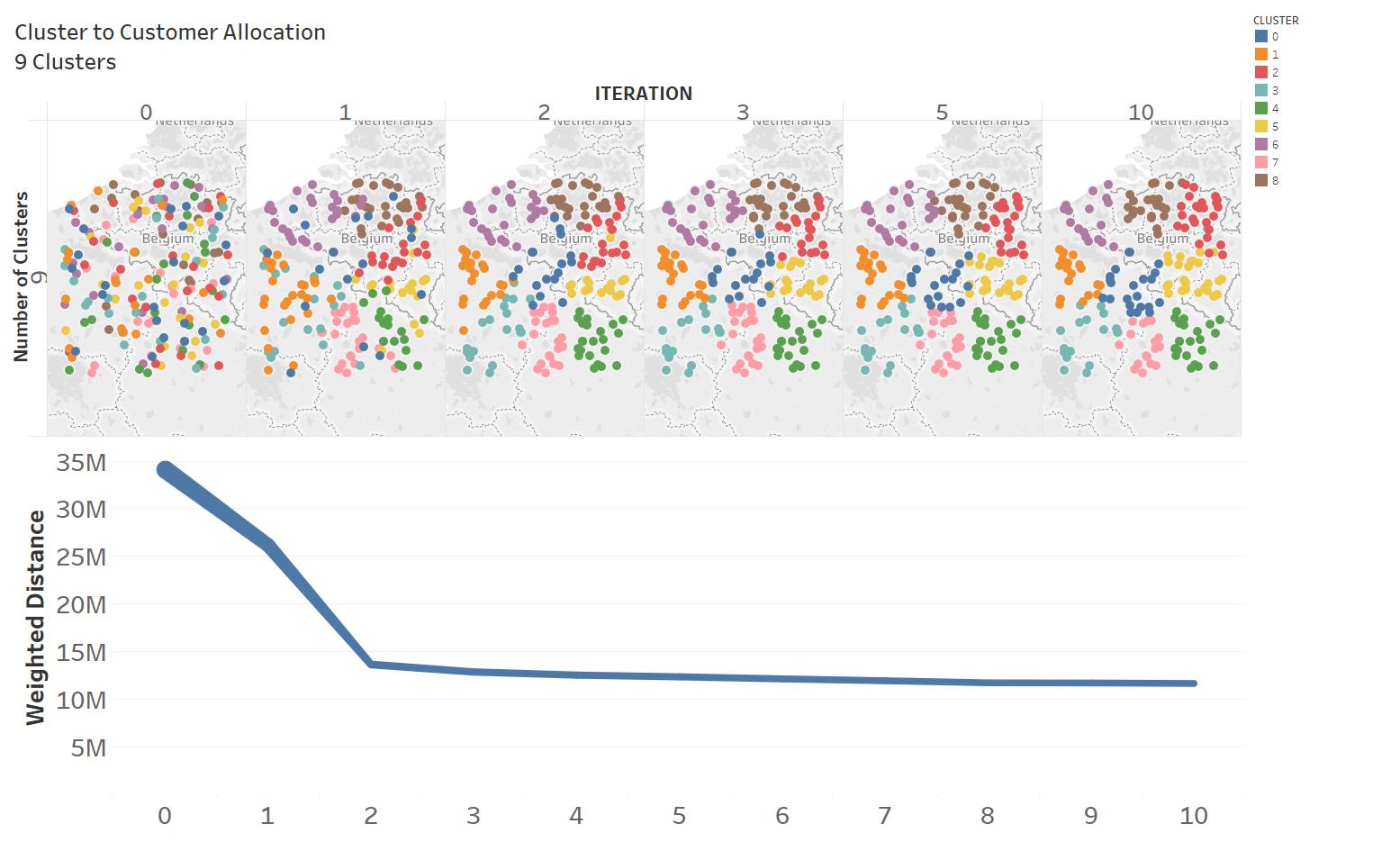 |
|---|
| Figure 3: Algorithm iterations for |
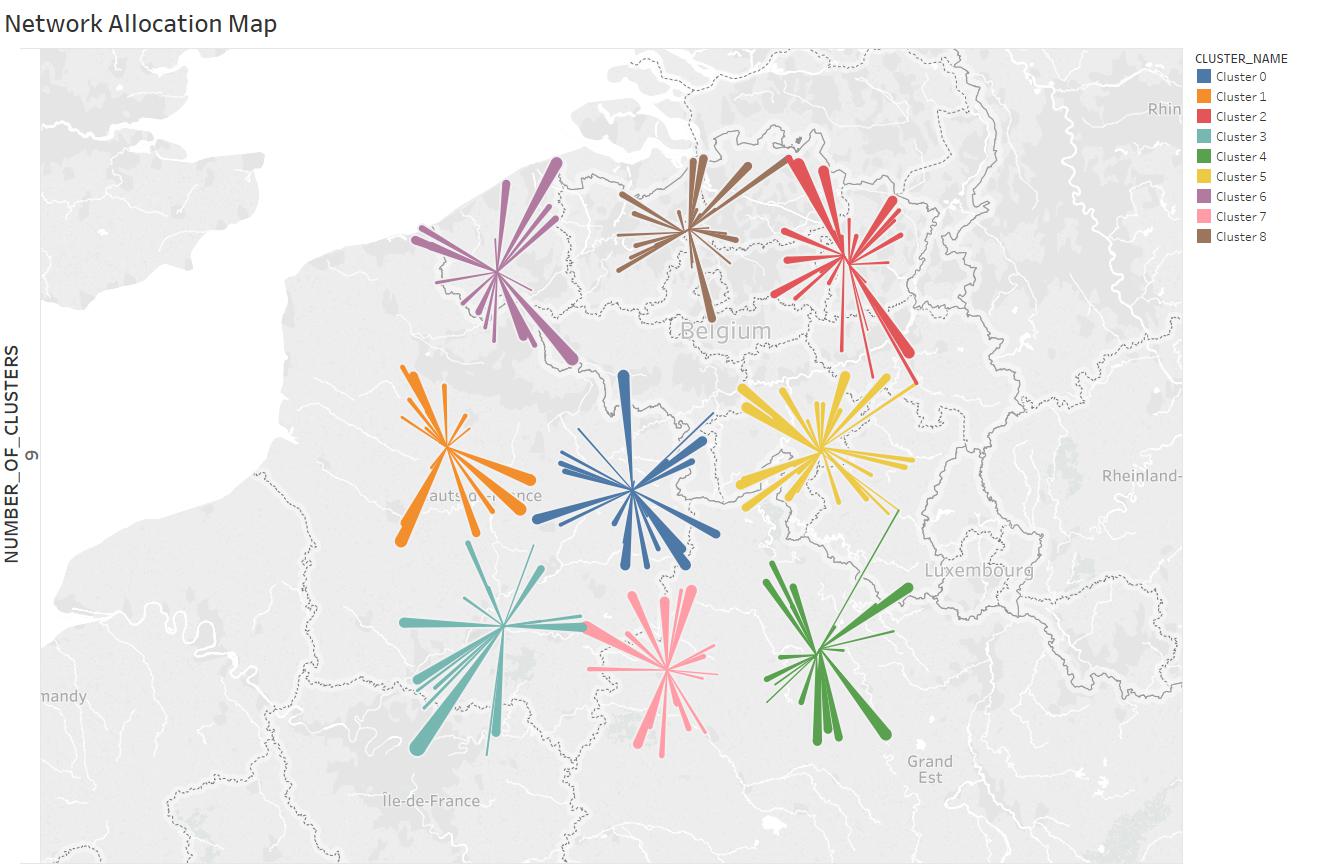
Allocation of customers to distribution centers is shown in Figure 4 for and . Each distribution center covers customers in average miles radius.
 |
|---|
| Figure 4: Optimal flow map for and |
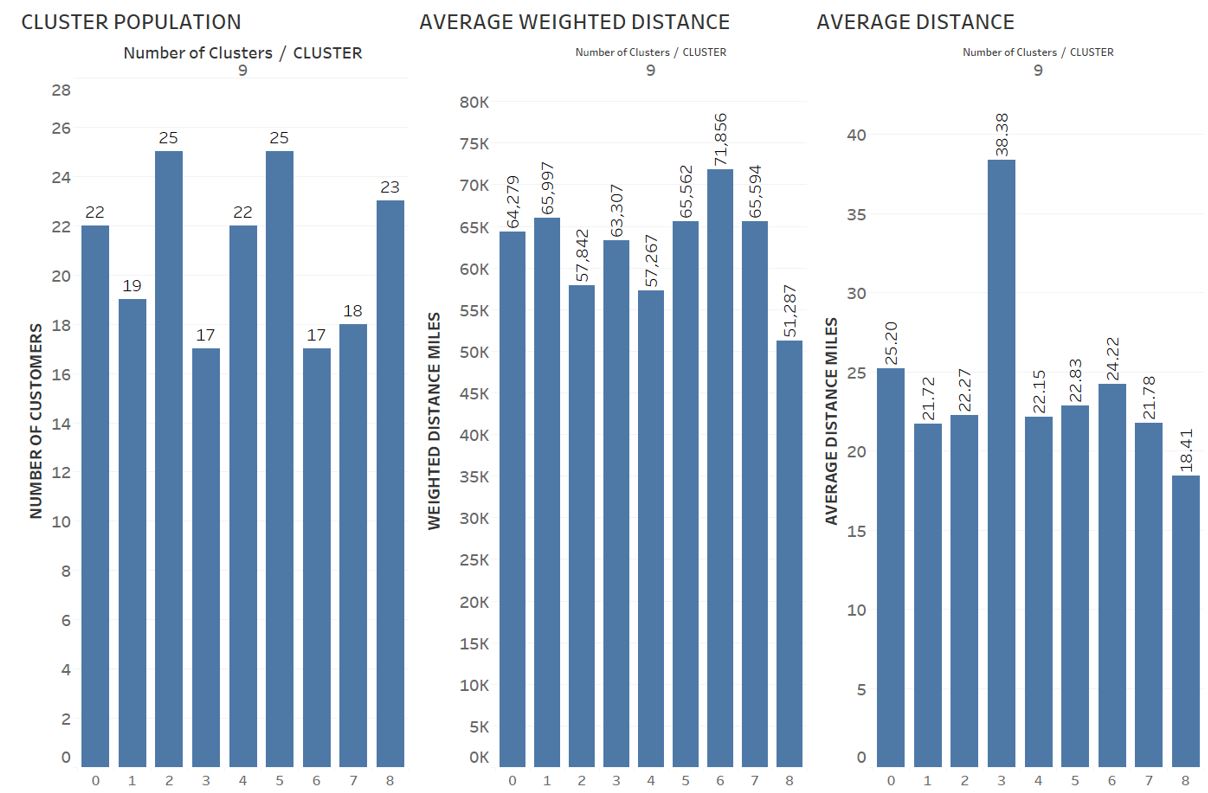
Figure 5 shows cluster statistics for . We bound cluster size as 20% of average cluster size which is minimum and maximum for . Cluster 8 average weighted distance is the lowest among all other clusters as well as the average distance.
 |
|---|
| Figure 5: Cluster statistics for |
Future Work
The Algorithm can be generalized to start with given instead of creating randomly. This will help to improve solution quality as well as to cover broader network design problems than the greenfield analysis.